Introduction & Problem Definition
The spread of AI-generated media demands accessible and accurate deepfake detectors. Most research evaluates deepfake detectors on research-oriented datasets generated by specific models or tampering techniques. Our analysis instead focuses on developing deepfake detectors for a new “in-the-wild” benchmark, Deepfake-Eval-2024. We demonstrate how the simple approach of adapting large foundation vision models pretrained on CLIP and finetuned gradually with cosine annealing produce generalizable deepfake detectors. Our best deepfake detectors set a new standard for open-source models – 81% accuracy onDeepfake-Eval-2024 – outperforming previous open-source models by 12% and closely competing with leading commercial deepfake detectors. Our approach offers tradeoffs in computational performance and interpretability, highlighting how costly and practical these deepfake detectors might be when deployed in real-world settings.
We have achieved the following in our project:
-
Developed high-performing deepfake detectors: We adapted large, pretrained vision models (ConvNeXt, ViT-b32, and ResNet-50) to create deepfake detectors that are highly generalizable and effective on “in-the-wild” deepfakes.
-
Achieved state-of-the-art results for open-source models: Our best model achieved 81% accuracy on the challenging Deepfake-Eval-2024 benchmark, outperforming previous open-source models by 12% and nearly matching the performance of leading commercial detectors.
-
Evaluated on a realistic benchmark: We conducted our analysis on Deepfake-Eval-2024, a new benchmark dataset of deepfakes and real images collected from social media, which provides a more realistic and diverse evaluation than traditional research datasets.
-
Found that slow, gradual fine-tuning is key: Our experiments showed that fine-tuning models pretrained on CLIP, using a technique called cosine annealing with a slow learning rate, was crucial for achieving high accuracy and generalization.
-
Analyzed model tradeoffs: We explored the practical tradeoffs of using different foundation models, highlighting that the Vision Transformer (ViT-b32) offers a superior balance of high accuracy and faster inference speed, making it more suitable for time-sensitive applications than ConvNeXt.
-
Visualized how models make decisions: We used GradCAM visualizations to show that different models focus on different parts of an image when making a prediction, suggesting that combining multiple model architectures could lead to even better performance.
GradCAM Visualizations (important regions in blue)

Best Validation Accuracies from Hyperparameter Tuning

Test Accuracy and Computational Performance
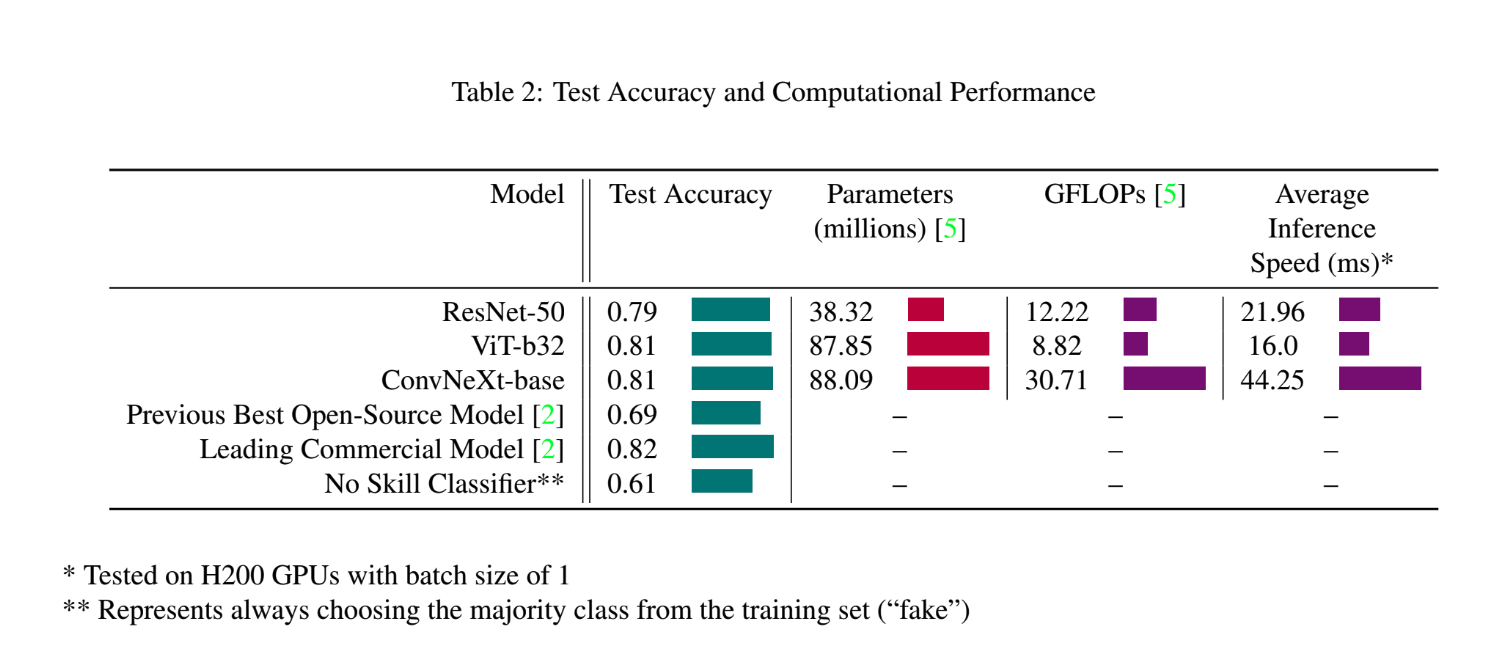
Performance on Test Data